Build scalable application policies
Policies in the cloud-native 1.0 world
In a previous post, we described how we envision cloud-native initiatives reaching the 2.0 phase, where phase 1 was centered around providing clusters and running its underlying infrastructure effectively.
Now that teams are starting to move some of their existing services to a microservices architecture, developers and platform engineers are being tasked with implementing the right policies and governance controls to ensure applications are running as securely as possible.
It can be a daunting task to understand, implement and manage the proper governance controls on Kubernetes. Without the right policies and rules, your applications and platform can expose several risks and vulnerabilities, which brings an incredible amount of pressure on the developers and platform engineers.
While some tools are available to help you achieve the desired state when it comes to governance, they are designed and engineered to address the requirements of phase 1.0. As we move towards phase 2.0 of cloud-native, it changes the focus to the application layer rather than the infrastructure, these tools become hard to manage at scale.
They are focused on the cluster object level rather than the application. Some require you to learn new development languages or infrastructure definitions. They will also require you to write and maintain a large set of rules, which will add tremendous complexity and open space for vulnerabilities and errors as you scale to hundreds or thousands of services and applications.
Kubernetes centric solutions will impact scale
While Kubernetes is the desired architecture, the reality is that applications are still distributed across virtual machines, cloud nodes, and Linux servers, so implementing these new tools will create additional complexity as you can’t use them with a number of your existing applications.
Challenges like this bring us back to the need for evolving cloud-native initiatives to a new phase, where the application is the focus. For the platform engineering team to be successful in supporting their organization in implementing a microservices architecture, they need to enable their developers to continue focusing on their application code rather than infrastructure while keeping tight control of how these applications are being deployed.

It is also vital to establish workflows that will enable platform engineers to tackle different security requirements from teams and applications without writing and maintaining a never-ending amount of complex rules. You should define application-level workflows that apply to Kubernetes clusters and servers distributed across diverse infrastructures.
This approach will allow you to scale while keeping your developers out of this complexity, so for them, what matters is the application code rather than the underlying infrastructure the platform engineering team chose to use.
Implementing policies for cloud-native 2.0
While different rules can ensure your applications are running safely, below are some of the most common ones implemented by users and how different they look when comparing phase 1.0 and 2.0 of cloud-native.
Trusted Repo
A simple but powerful policy that ensures application images are only pulled from trusted repositories. By limiting which repositories can be used by developers, platform engineers can control the image inventory while ensuring that unknown images are not used, mitigating several risks.
Implementing this with Open Policy Agent (OPA) would look like this:

Implementing this with another option, Kyverno, would look like this:
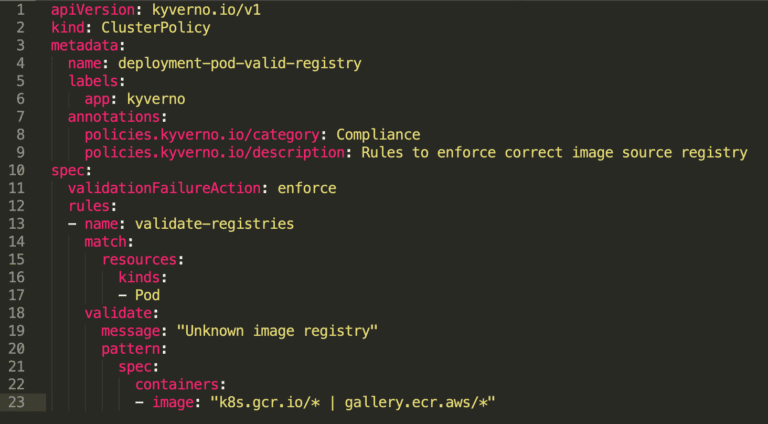
Implementing it with Shipa and an application approach rather than Kubernetes:

Because Shipa uses a cloud-native 2.0 approach, you can apply the rule above to Kubernetes and Linux nodes. This can also be defined using Shipa’s UI:
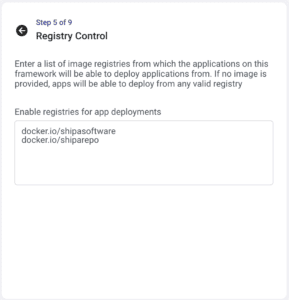
Ingress Policies
Ingress policies allow you to limit how services are exposed or even don’t allow them to be exposed at all.
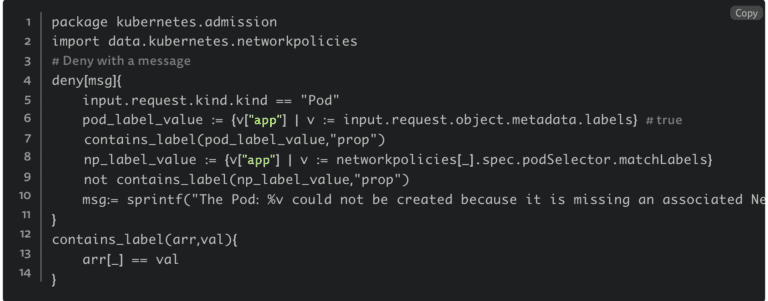
Let’s say you want to limit the communication between two different applications. By using the approach from phase 1.0, Kubernetes-related you would need to first create a network rule directly on Kubernetes, which would look like this:

Next, you would need to create an OPA rule similar to this to ensure the rules exist when applications are deployed:
Implementing a similar policy using the new application-centric approach through Shipa would look like this:
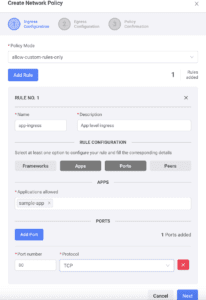
You can notice above that, as a user, you don’t need to create Kubernetes-related objects. Shipa will make sure the policies are always in place when applications are deployed, which also removes the need to develop a specific OPA policy just for that.
Egress rules would be the same approach between cloud-native phases 1.0 and 2.0Sign Up for Shipa Cloud
Resource Limits
Like the previous section, proper handling of resource limits would be a combination of Kubernetes objects creation and OPA rules to ensure the objects exist so that the resource limits can be applied to the applications.
Creating the resource limit on Kubernetes:
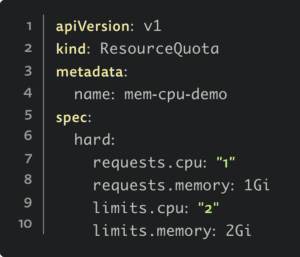
Then next, you would need to create the OPA rule to ensure the policy exists:
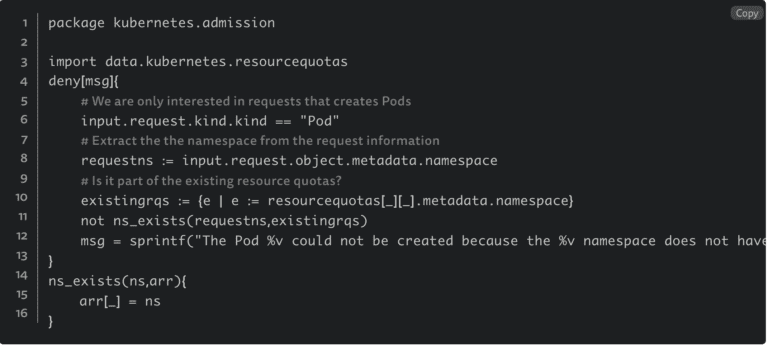
Creating a resource and a rule to ensure the resource exists may seem easy to start. Still, as you scale across several clusters, face different requirements for different apps and teams, this will end up being part of the unnecessary complexity that platform engineers need to deal with on cloud-native 1.0.
Using the application-centric approach would look like this instead:

Like the previous example, you don’t need to create and manage Kubernetes objects for this and write and maintain OPA rules. It’s also important to notice that the resource plan created can be applied across different Kubernetes clusters and Linux nodes.
What’s Next
Moving towards an application-centric policy definition will help you build standards, address requirements across applications deployed on different infrastructure, and help you scale in a more structured way.
We invite you to be part of this new phase, try Shipa, and help us build a new application-centric standard that will drive cloud-native 2.0.
You can create an account here: Create an Account
In the next post, we will discuss how Shipa’s policies engine, called frameworks, is designed to apply standard rules across multiple clusters and nodes.