TL;DR
- Assuming or hoping every developer and application support team in your organization knows Kubernetes well is not a strategy.
- As teams can’t support applications because they are not comfortable with the underlying infrastructure or because of scale, the pressure and toil on the DevOps team will keep increasing
- Giving teams access to your clusters to troubleshoot applications may not be the best strategy
- You can implement a scalable application support model in just a few minutes and without changing any of your pipelines and infrastructure
- Centralizing application management from multiple clusters, pipelines, and teams in a centralized application platform will reduce DevOps toil, increase dev productivity, and improve application support time.
Supporting Applications
I’m sure you have seen many guides with cheat sheets for getting up to speed on Kubernetes and kubectl basics. I have found those fantastic resources for teams building, delivering, and supporting Kubernetes clusters.
In contrast, I have seen limited resources for teams supporting applications. I’m sure most of you have come across the picture below:
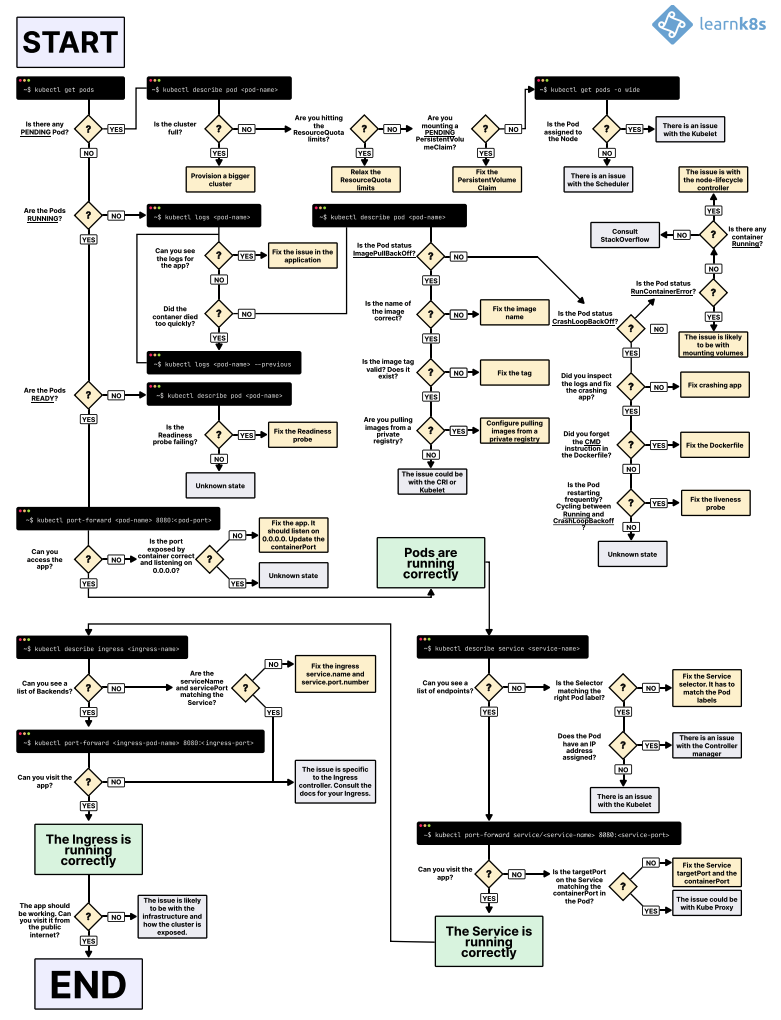
While we, engineers, love a nicely done diagram and get the feeling it gives us super powers when we memorize all those steps and individual commands, this workflow presents a few challenges:
- It assumes developers and anyone else supporting applications will have access to your clusters. We can all agree that this is far from ideal and handling RBAC in Kubernetes at scale is another challenge.
- As you scale the number of applications deployed in your cluster and developers/SREs managing those applications, it’s tough to assume everyone will know Kubernetes infrastructure details, ingress, services, etc. This will cause application support times to increase, the load, toil, and stress on the DevOps team will increase, and your goals of a developer self-service platform will be gone.
- While Git may be your source of truth, finding and accessing an application’s historical information will be a nightmare. As you scale pipelines, teams with different SLAs and security requirements are onboarded, and more, the scales of complexity kick in.
- One service down can very well impact others. Understanding service to service relationships at scale using the workflow above will certainly impact application owners from understanding the blast radius or its impact on other services.
- Onboarding developers, DevOps, and SREs, will be more challenging as you scale as it will be challenging for them to quickly understand all applications, owners, service relationships, etc.
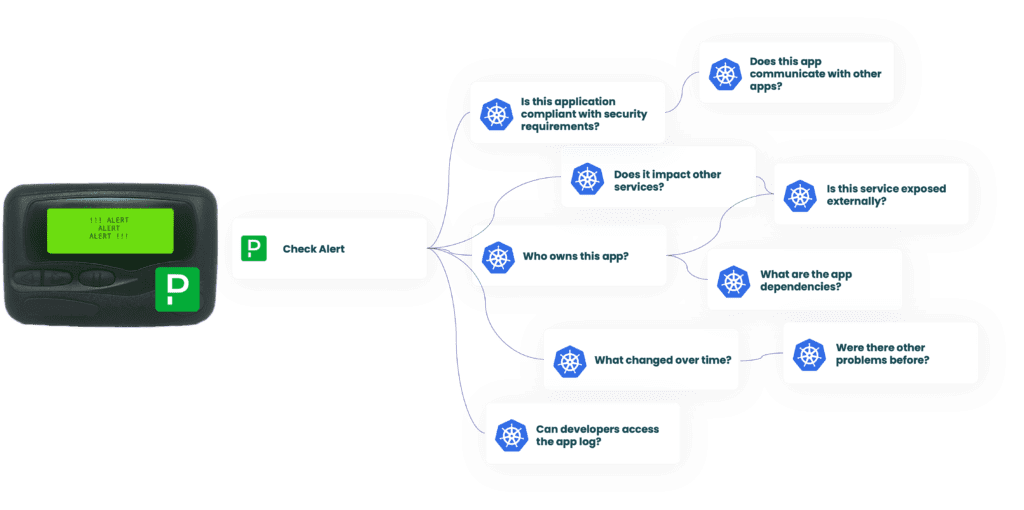
Bottom line, our goal is to implement a self-service application support model that exposes all required information so teams can support their applications quickly while reducing the toil on the DevOps side, so you can focus on scaling.
The section below will guide you through implementing that model without making a single change in your clusters, pipelines, automation, etc. You will give developers and SRE teams a multi-tenant application platform they need to support their applications effectively.
You will look good, eh?
Architecture
We will assume the sample architecture below:
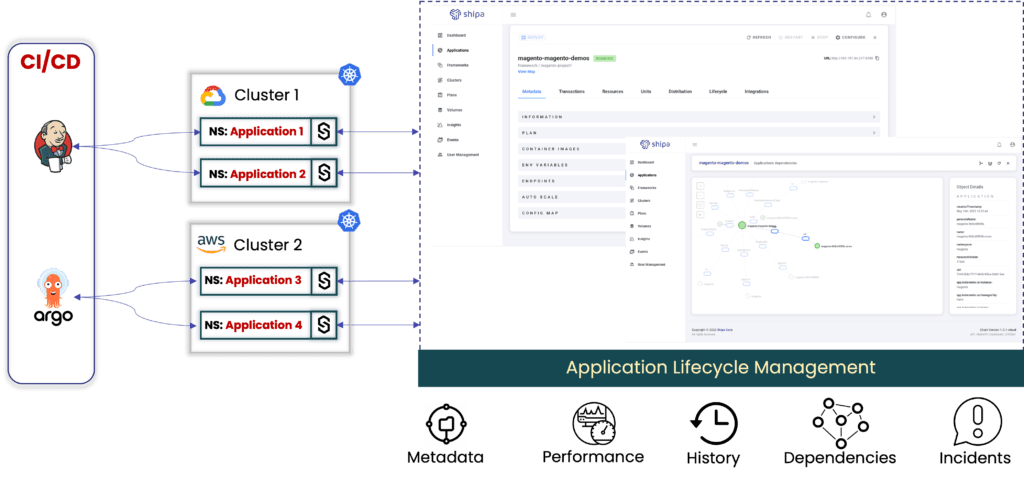
You will:
- Centralize application information from multiple clusters into a single application platform
- Remove the need to give developers access to your clusters
- Enable teams to get instant details about service ownership, health, dependencies, logs, etc.
- Record application history, so any changes such as new deployments, errors, restarts, and more will be recorded as the application’s lifecycle so teams can understand what happened to the application over time. This is great for application support and regulated industries that need access to every application change and log.
Regardless of the pipeline you used, Jenkins, ArgoCD, FluxCD, or others, Shipa will standardize the application management layer and help you keep on evolving your pipelines and infrastructure without impacting how teams manage and support their applications.
Getting Started
We will use Shipa as the application platform. You can create a free account on Shipa Cloud here.
Once you log into Shipa’s dashboard, head over to Frameworks and click on Create
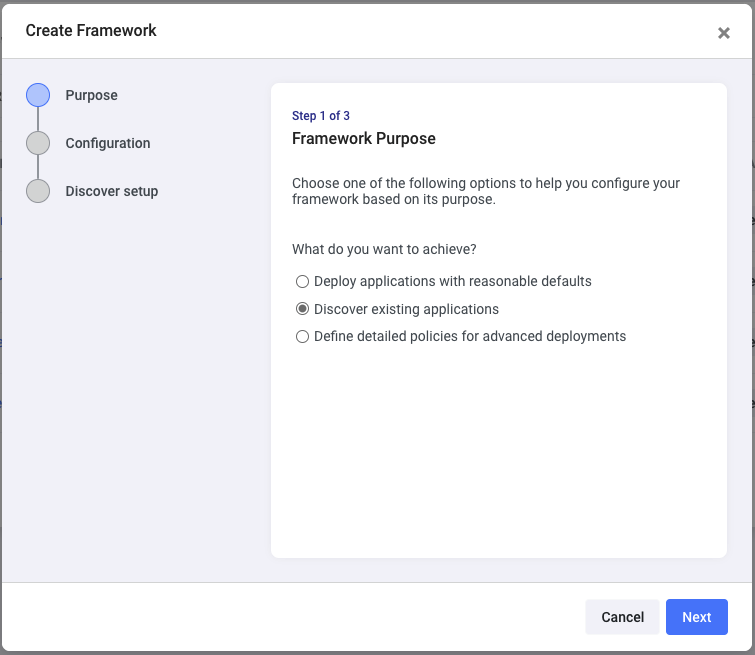
Shipa uses Frameworks to connect to your clusters, discover applications, and enforce and report on policy violations (more on that in the following post). Frameworks connect to a namespace in your cluster.
Go ahead and select the Discover existing applications option
Here, you have to enter:
- Framework name: This can be the name of the application, team, or environment you want to discover. Remember that this will connect to a namespace in a destination cluster.
- Plan: This is part of Shipa’s policy Insight functionality. For now, select the shipa-plan option, which is provided with every new account.
- Kubernetes namespace: The exact name of the namespace you want to connect this framework to.
- Teams: The teams you want to give ownership and visibility over the applications discovered by this framework. You can create teams, invite users, and assign permissions here.
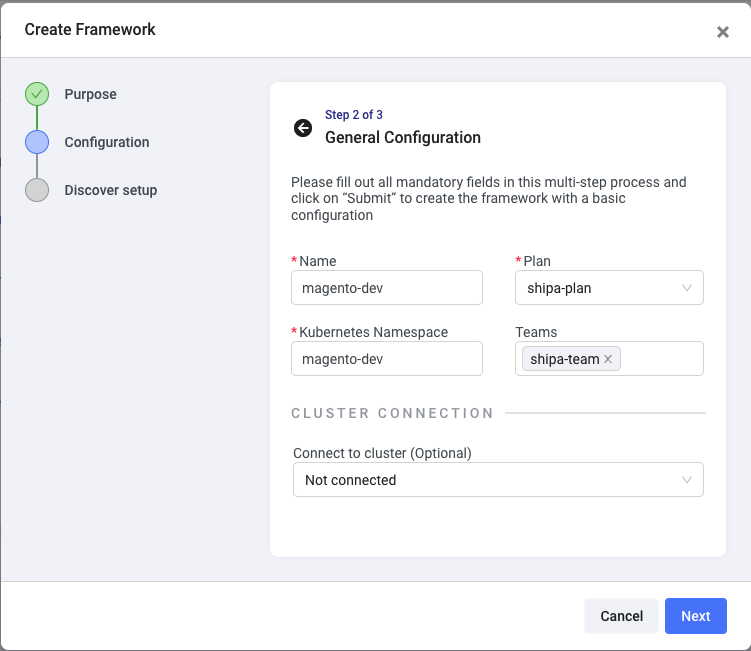
Click on Next
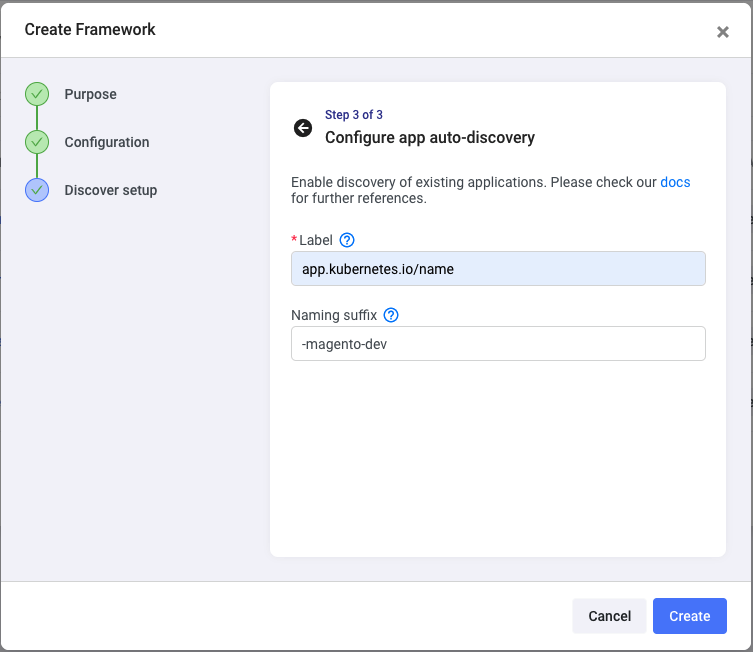
Enter the label defined by your deployment scripts so that Shipa can discover the applications deployed in that namespace.
Suppose you use frameworks to discover applications with the same name across different namespaces. In that case, you must define a naming suffix so that Shipa can distinguish between the applications.
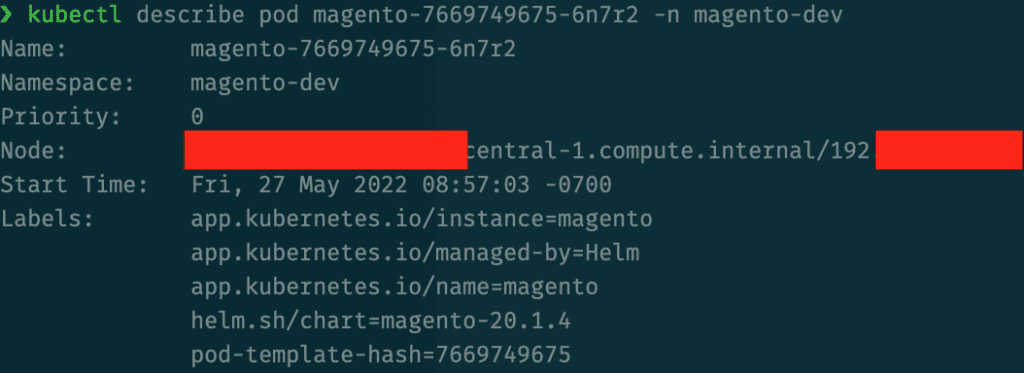
** You can find the labels assigned to your applications by using kubectl describe pod pod-name command and looking for the Labels section:
Click on Create
You can create multiple frameworks to be connected to different namespaces if you want.
Head over to Clusters and click on Create
Choose the framework or frameworks you want to connect to your cluster, enter your Kubernetes control plane address, and click on Generate Command.
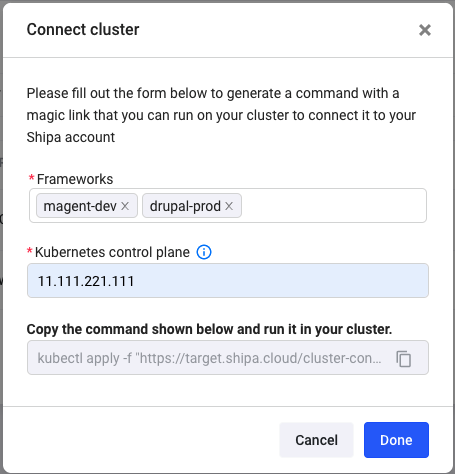
Shipa will generate a kubectl command. Make sure your local kubectl context is set to the destination cluster and run this command:
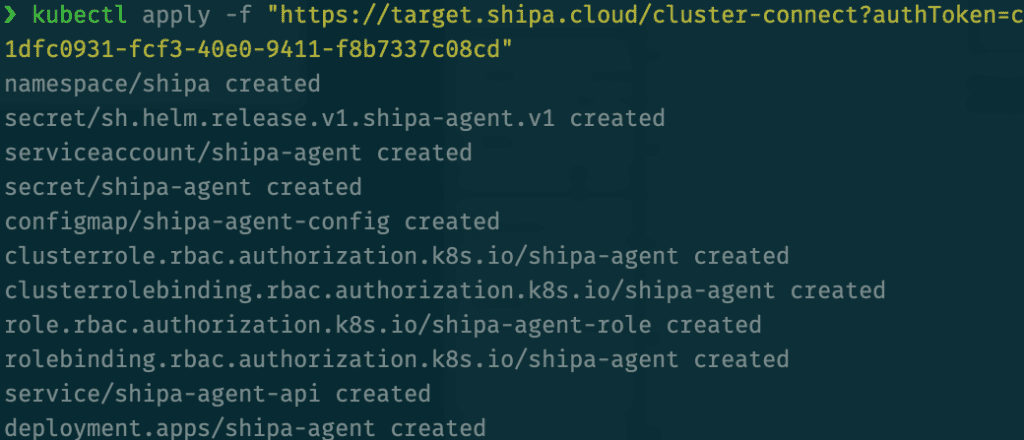
Shipa will create a namespace in your cluster, install its agent, and start scanning the desired namespace for applications using the label you defined when you created the framework.
The process should take a couple of minutes, and you can follow its progress through the Events page of your Shipa dashboard.
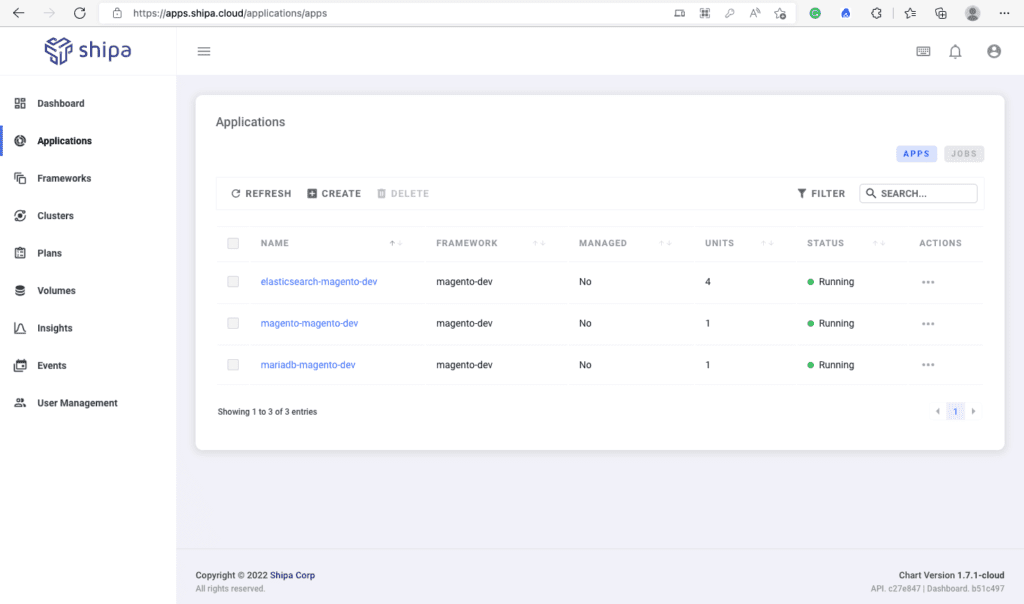
As soon as Shipa starts discovering the applications, you will see them available on the Applications page:
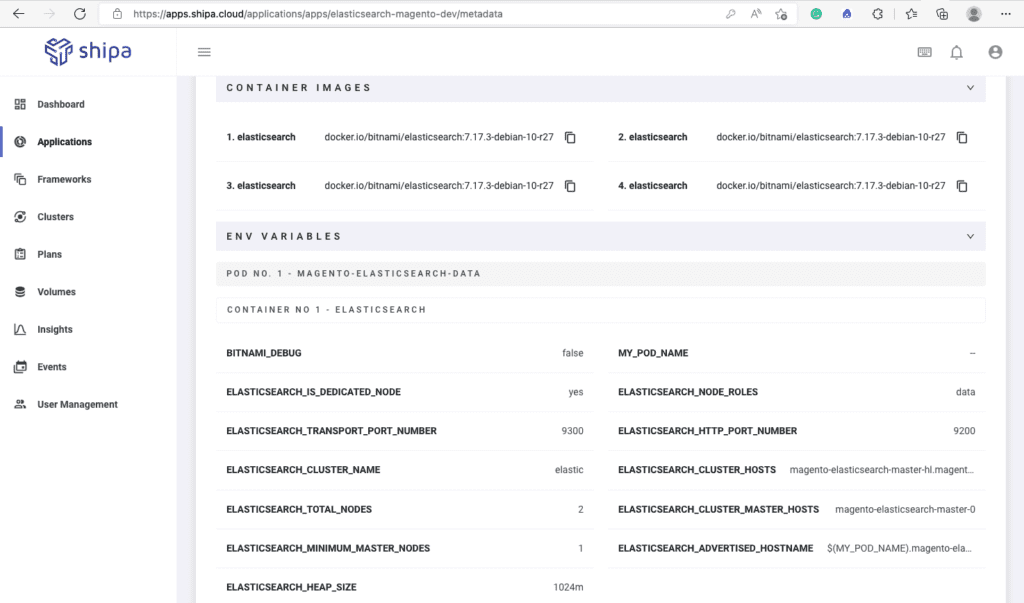
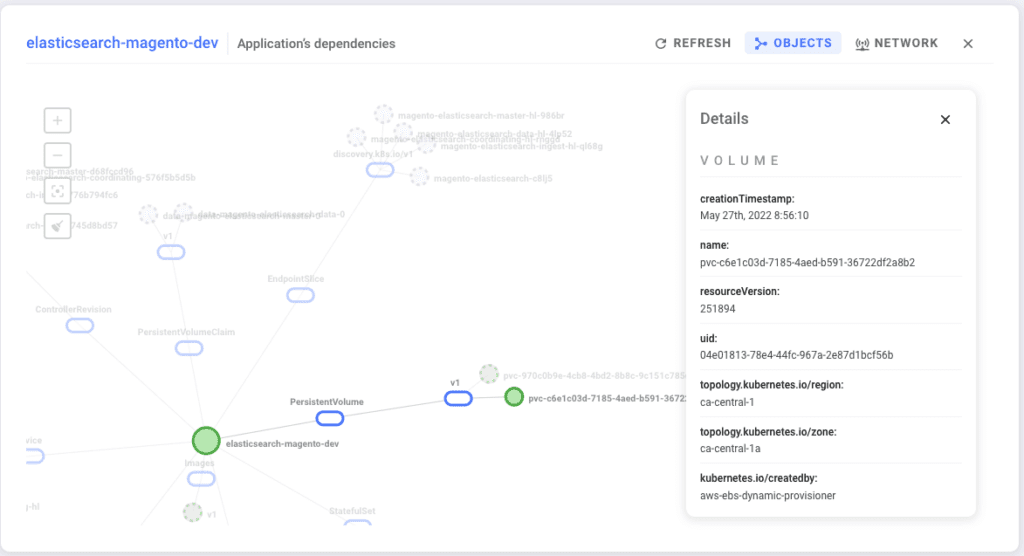
By clicking on the application name, you will have access to the application metadata, such as owner, container images used by this application, environment variables, endpoints where the application is exposed, etc.:
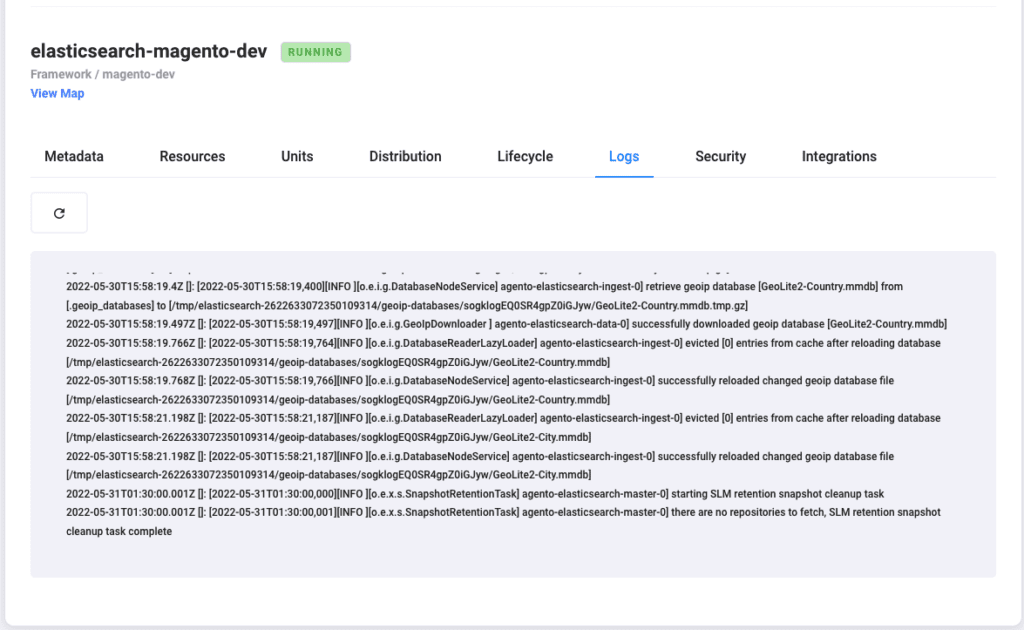
In addition, you have access to the application monitoring information, lifecycle (deployments, restarts, errors,…), unit information, logs, and you can integrate this application into your incident management systems so that teams can automate support and tracking of activity.
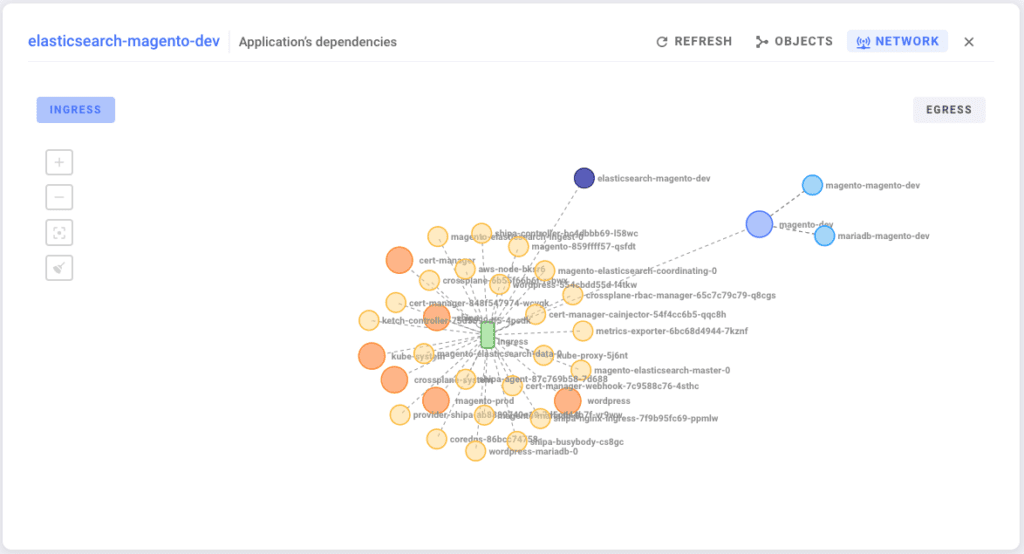
Your users also have visibility over the applications’ dependencies and how it communicates to other services. Should problems arise, they can quickly spot the dependency causing the problem or why their services can’t communicate with other applications.
Discovering Additional Applications
You can discover additional applications in the same or different clusters by repeating the steps above.
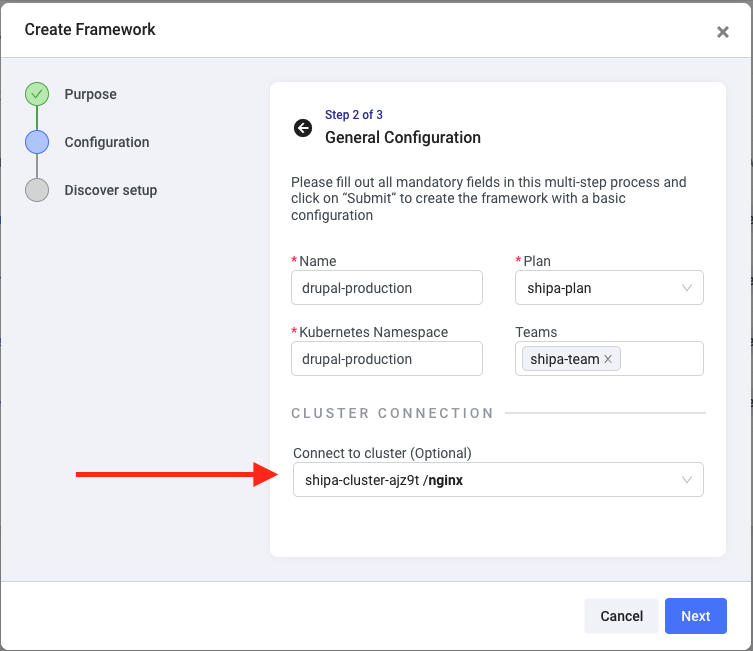
If you are discovering applications in the same cluster, a shortcut you can use is to select the cluster you connected during the previous steps when you are creating a new framework:
Conclusion
In just a few minutes and without making any changes to your infrastructure, you can enable your teams to support and manage their applications without dealing with the underlying infrastructure complexity and logging into your clusters.
This way, you can build a scalable application management model, make it easy for users to understand and support their applications, improve support times, and more.
In the next post, we will cover how you can use the approach above to find security vulnerabilities that these applications may be exposing across different domains.