Things would be much simpler if we based all we built on Kubernetes on a single tenant type of architecture, meaning a single application running on the entire Kubernetes cluster with a single team who could access it.
As teams scale Kubernetes adoption within their organizations, they see a different scenario instead, one with multi-tenant deployments performed by multiple teams and, most probably, across multiple clusters.
While this is possible when using Kubernetes, it’s pretty common to face resource allocation and security challenges.
Let’s walk through some of these challenges and strategies for addressing them.
What is Multi-Tenancy?
Multi-tenancy is a Kubernetes cluster architecture in which you share cluster resources among multiple tenants.
Examples of resources shared include CPU, memory, networking, control plane, and others. You can consider development teams, applications, customers, or projects as tenants.
Multi-tenancy is a helpful model for optimizing infrastructure cost, accommodating different types of users in the same cluster, hosting various applications, and reducing operational overhead and complexity.
When implementing a multi-tenancy model, you must ensure that each tenant has access to the resources they need. In addition to that, you must isolate each workload so that a security vulnerability or breach in one workload does not affect other tenants.
Addressing Multi-Tenancy
We will use Shipa to help us address our multi-tenancy requirements. If you don’t have an account on Shipa yet, you can create one free here.
Architecture
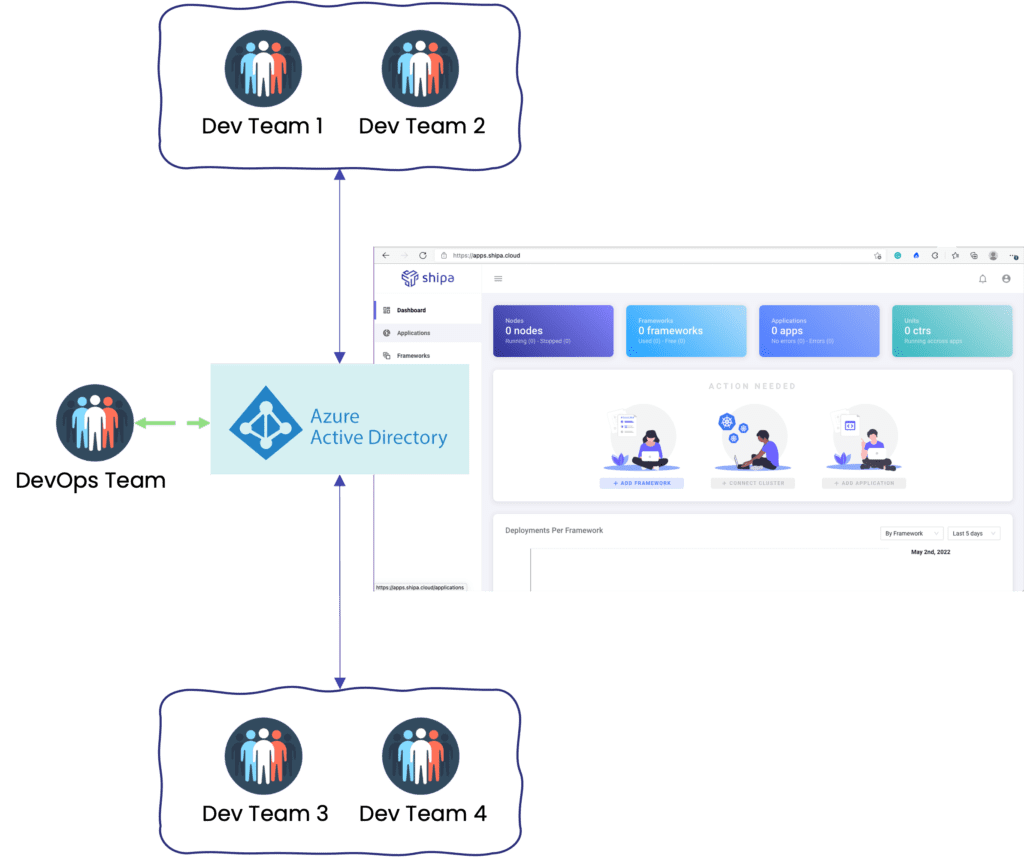
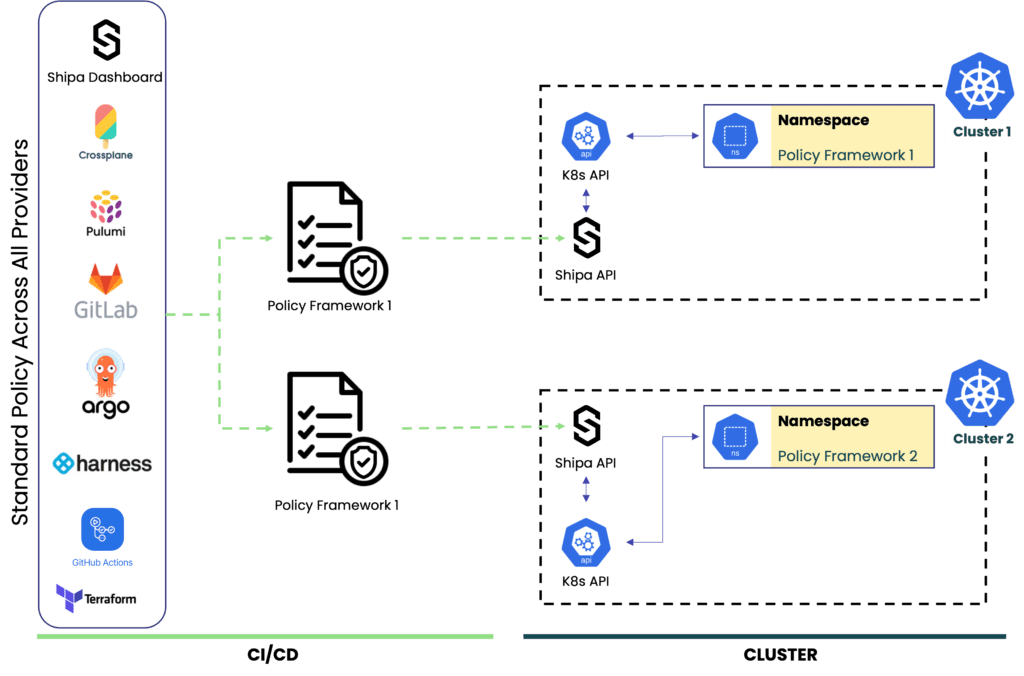
The picture below is an example of a multi-tenancy architecture we want to implement:
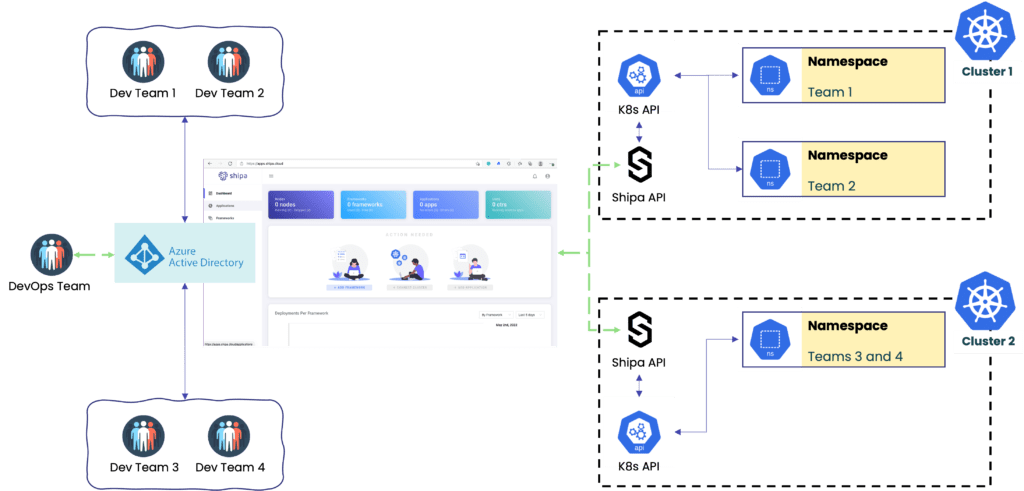
Let’s break down the components:
- Clusters: Multi-tenancy complexity scales as you scale the number of clusters. The model covered in this post will show how centralized information can help you scale infrastructure without scaling complexity.
- Developer portal: We will use Shipa Cloud’s portal so Developers, DevOps, and SREs can have centralized information about applications, teams, clusters, and more.
- Namespaces: The model covered in this post allows you to break things down into different clusters and namespaces where each namespace will have a different set of policies/limitations
- Authentication: We will use Azure Active Directory for centralized authentication.
- API Access: Using Shipa as the Developer Platform will remove the need to provide users with cluster-level access while giving them detailed application info they will need to troubleshoot their application.
This is a pretty extensive topic, so I may not cover the setup of every component in detail here but rather break it down into different posts.
Benefits
By implementing the architecture above, we expect the following benefits:
- Scalable multi-tenant architecture with a detailed tenant, application, and policy visualization
- Developers won’t need cluster-level access, drastically reducing the complexity of RBAC management
- Will connect to a central authentication server
- DevOps teams can quickly provision a secure environment for tenants
Role-Based Access Controls (RBAC)
One of the things we learned from experience is that giving your users access to servers was never a good idea. You might know very well how to operate clusters, troubleshoot applications, and more, but at scale, it’s pretty hard to assume that all users in your organization are well versed in Kubernetes.
In addition to the point above, I believe most of us can agree that managing RBAC directly in Kubernetes, especially at scale, can be extremely difficult.
Configuring Azure AD
Having your users go through an application-level API that enforces controls and policies while giving them complete application and policy visibility can undoubtedly help reduce risks and facilitates RBAC management.
So let’s provision our user structure. Shipa supports SAML, and for this example, we will connect Shipa to Azure AD.
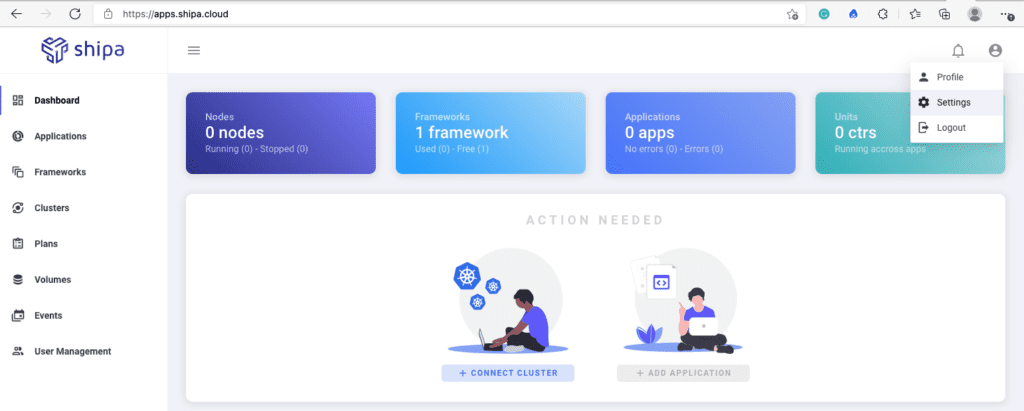
Once logged into your Shipa Cloud account, click on your profile icon and Settings. This will open a new screen with the Single Sign-On option. Clicking on Create will show you the form to enter your Azure AD information:
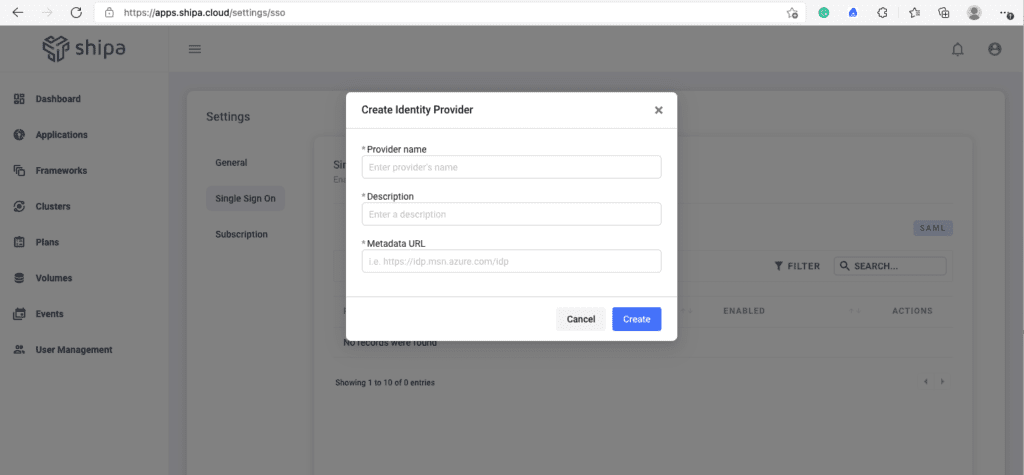
You can find detailed information on creating your identity provider connection here: https://learn.shipa.io/docs/sso-using-azuread.
Creating Teams
With your Shipa Cloud account connected to Azure AD, now you can start creating your teams. Head over to User Management by using the left menu and click on the Teams tab
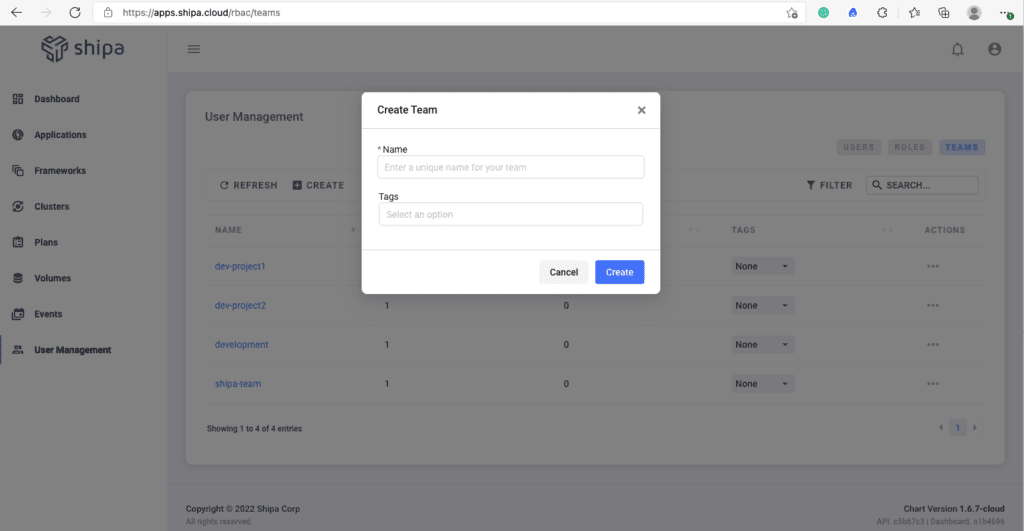
Clicking on Create will show you the form to enter the team name and any tag you may want to assign to it.
You can use this workflow to address the needs you have, may it be based on development and operations teams, projects, etc.
Adding Users and Assigning Roles
With your teams created, you can now invite users. Click on the Users tab. You can invite users through the Invite button:
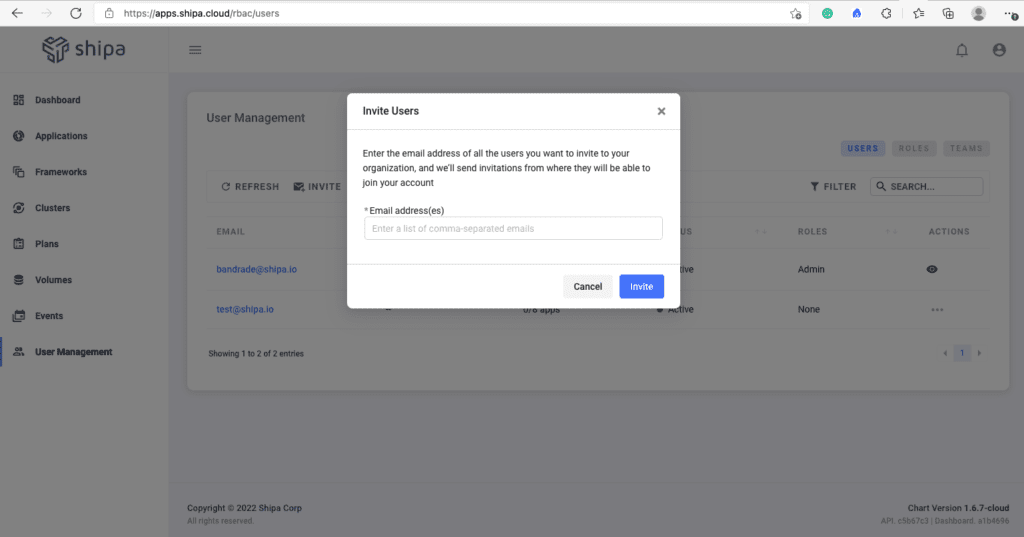
This will send an invitation to the email you entered and the login information your user needs to access Shipa. They will be able to use their Azure AD credentials to log in.
Once the user is invited, you can click on the user menu option and choose Roles to assign the user a role:
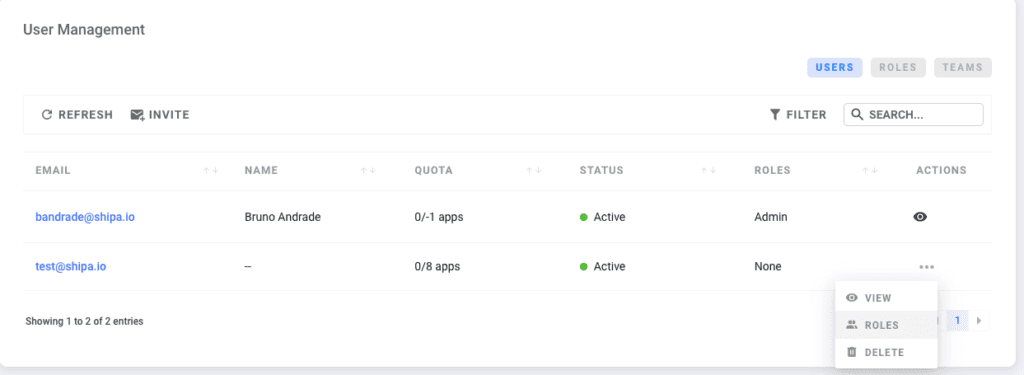
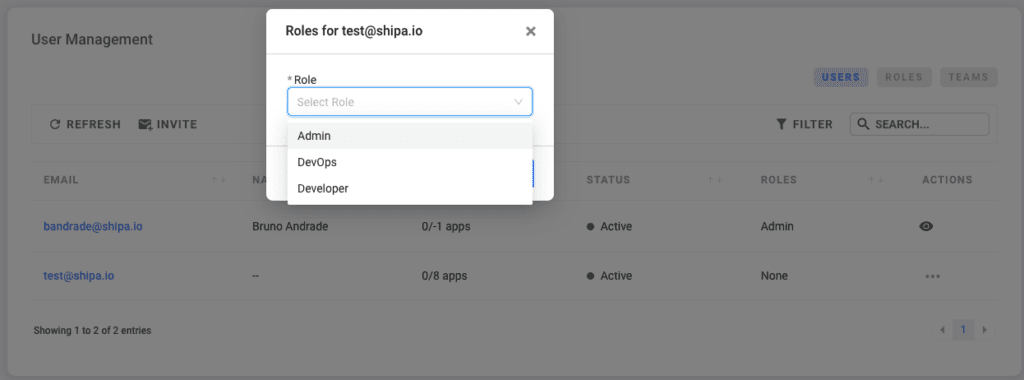
Although you can use the Shipa CLI to create roles and assign permissions, the Shipa dashboard has three canned roles you can use to speed up the onboarding of users into the platform: Admin, DevOps, and Developer.
With that, you have now:
- Connected your Shipa account to your Azure AD provider
- Created multiple teams
- Invited users
- Assigned roles to your invited users
Multi-Tenancy Cluster Setup
Now it’s time to address where applications are deployed and the level of security you want to enforce.
Securing a multi-tenant environment goes well beyond just security scanning, and doing that at scale can be extremely complex if you don’t have a structured security workflow.
Shipa has a concept called Frameworks, which is how Shipa connects to your Kubernetes cluster and how it enforces security at the namespace level.
By leveraging Shipa’s framework, you will be able to address:
- Isolation: each framework you create and connect to a cluster becomes a namespace in your cluster. Every application deployed by developers pointing to this framework will automatically be deployed in the namespace where the framework is connected.
- Standard definition: defining policies across multiple pipelines, IaC tools, and clusters at scale can be daunting. Implementing a standard policy definition across RBAC, networking, resource limits, and more across multiple pipelines will drastically reduce complexity and make it easier for anyone in your team to manage policies.
- Root users: by default, applications deployed pointing to a Shipa Framework will never run as root.
Creating Frameworks
The process of creating frameworks and connecting them to your cluster is straightforward. The unique approach Shipa brings to this is that it presents you with a detailed workflow to help you address so many security issues from a single point of view.
Even though you can create frameworks directly from your pipeline using your IaC or pipeline tool of preference, such as Terraform or Pulumi, we will use Shipa’s dashboard to give you a complete picture of some of the options you can use when automating this process.
Click on Frameworks and then Add Framework using the left menu:
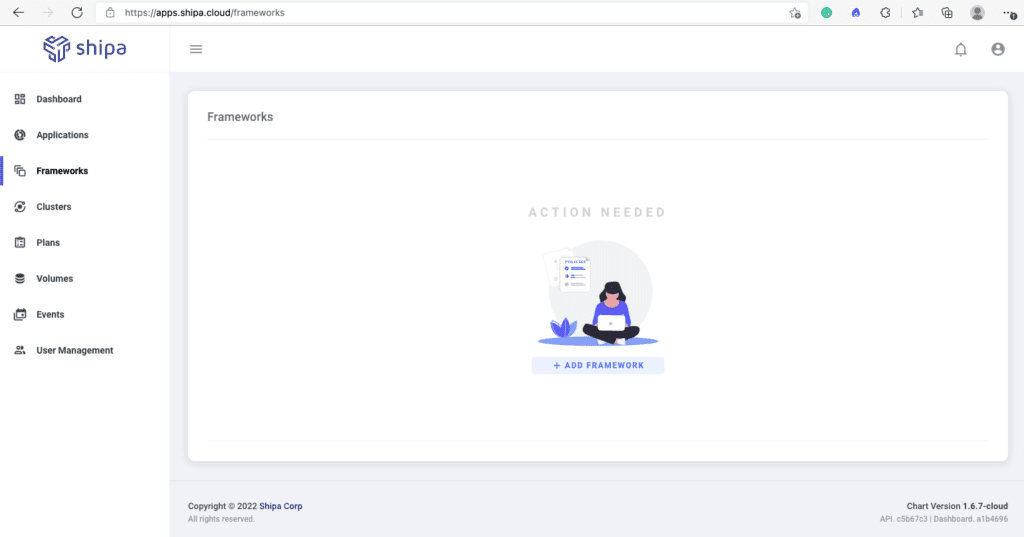
Shipa will give different options that you can use to address basic or detailed security requirements. Click on the Define detailed policies option to see all possibilities you can easily address:
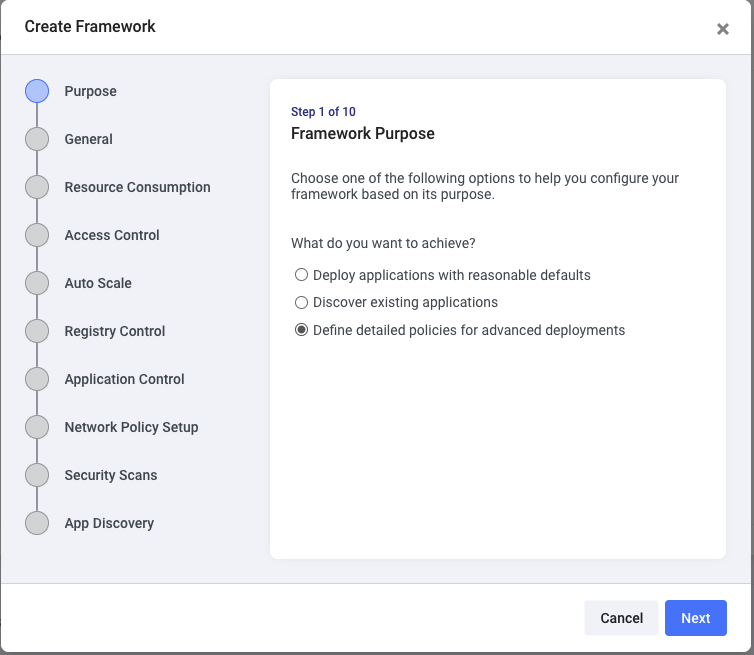
The first step of the workflow will allow you to name this framework. Be creative and use it to address requirements such as environment level framework, project-level, team-level, or others.
Specifying a namespace name is not required. If you don’t specify it, Shipa will automatically create a namespace named shipa-framework-name for this framework when you connect it to a cluster. If you specify a namespace name, Shipa will connect this framework to that existing namespace, or if it doesn’t exist, Shipa will use the namespace name you entered here.
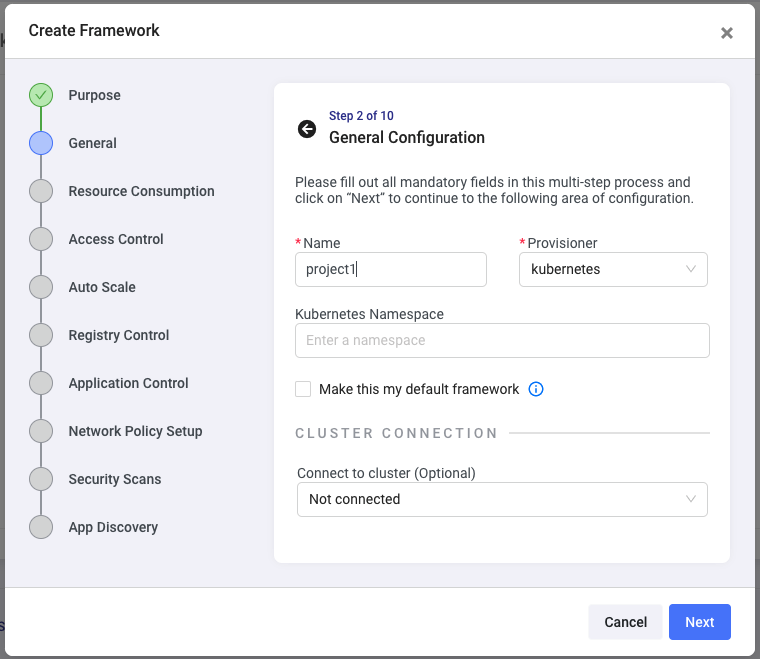
Clicking on next will allow you to assign a resource limit plan. By default, Shipa creates a plan called shipa-plan, which does not implement any limits, but you can create additional plans here.
This means that every application deployed using this framework (to this namespace) will automatically have these limits enforced.
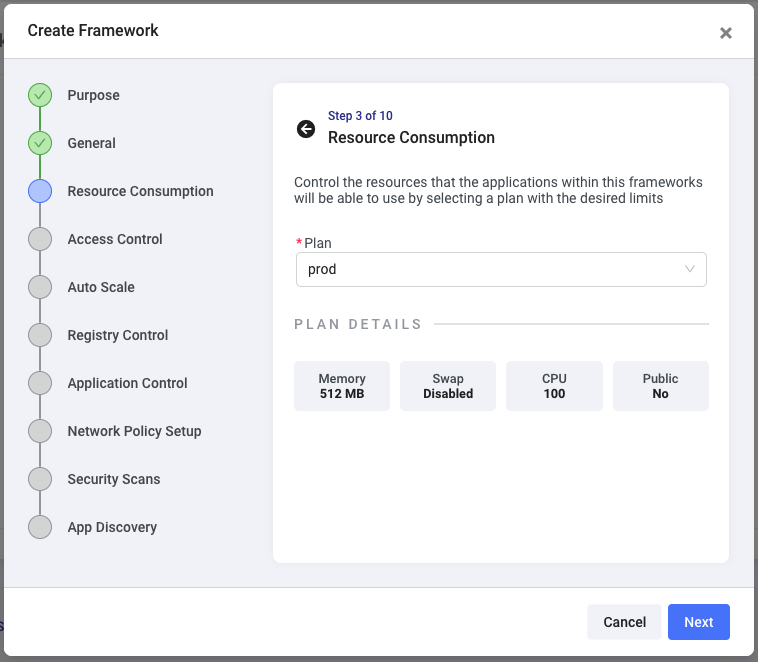
The next step will allow you to define which team (or teams) can deploy applications using this framework (to this namespace). You can use any or all the teams you created in the previous step:
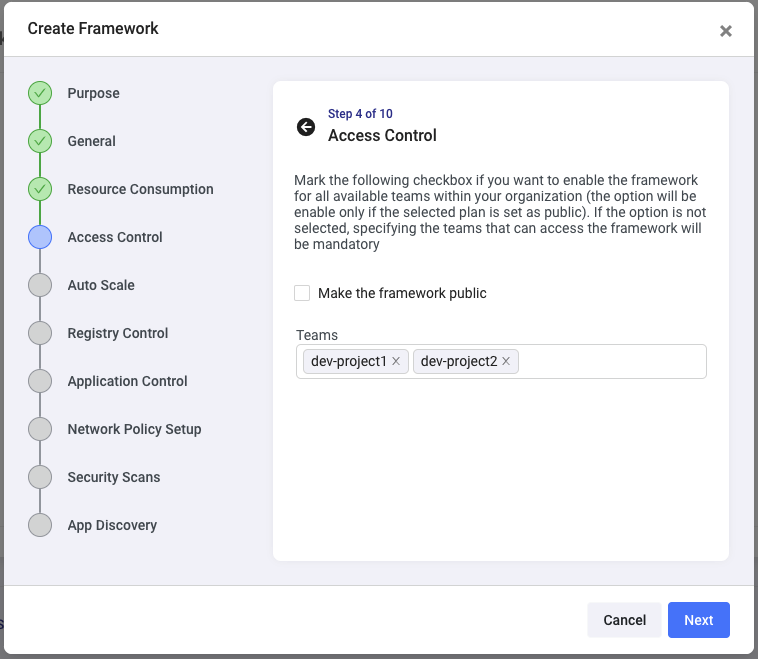
The Auto Scale step will allow you to enforce automated autoscale rules for all apps deployed using this policy, so if this is a production type of framework, you can ensure that every application deployed will automatically scale based on the metrics you define here:
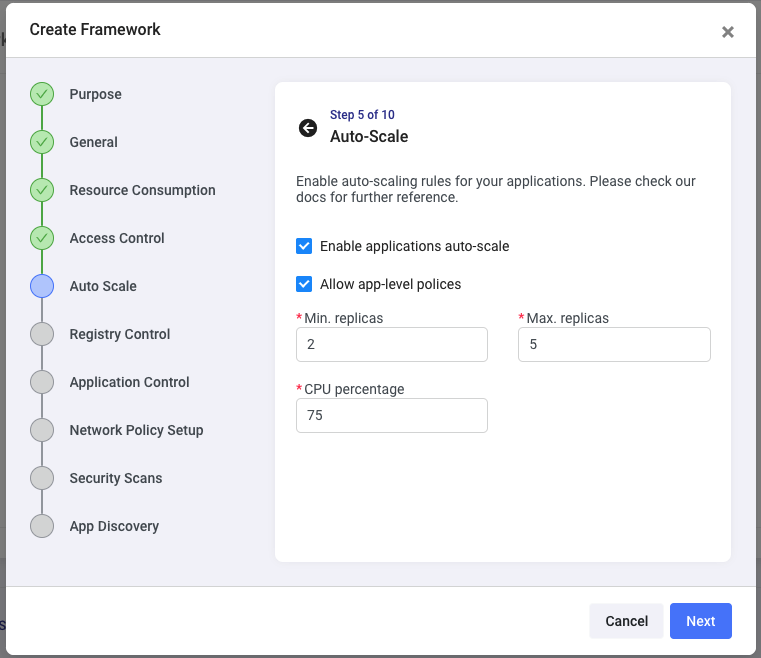
By clicking on Allow app-level policies, you give application owners the capability to customize this rule for their specific application without changing the autoscale rule for all other applications deployed using this framework.
The next step will allow you to define registry control, limiting developers on which registries they can use when deploying applications using this framework. You want to use this to make sure that no publicly available images will be deployed into production, for example:
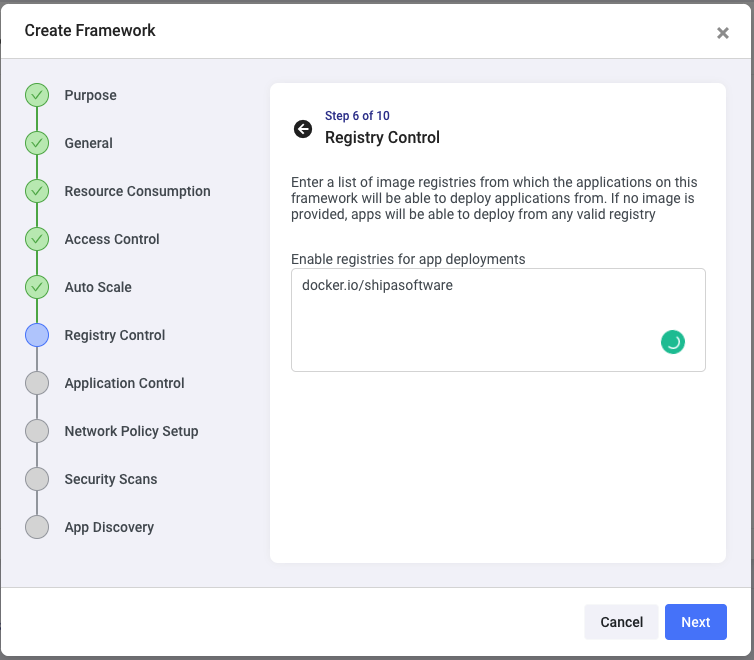
The Application Control step allows you to set up node selectors and limit the CNAMEs developers can use to expose their applications.
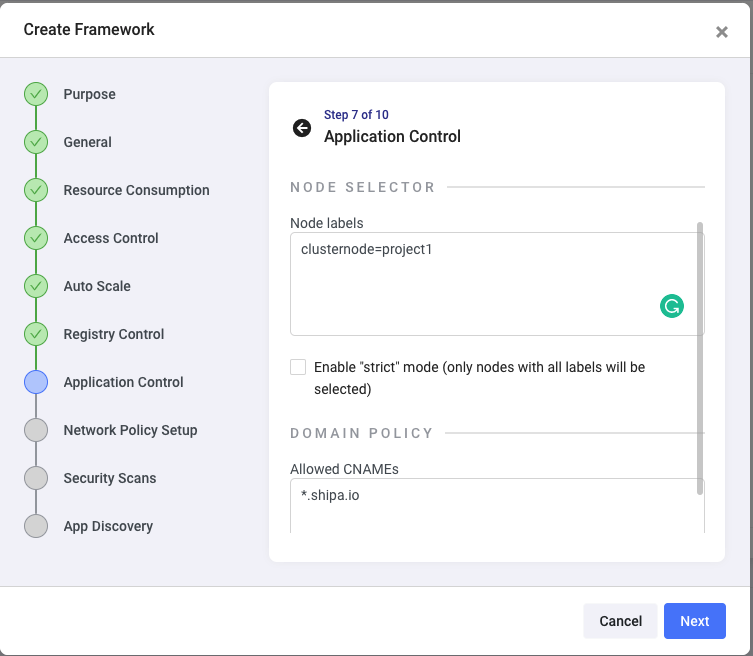
This helps you to:
- Make sure applications deployed using this framework are only deployed using certain nodes, which is great in case you are using clusters with a large number of nodes and want to segregate what goes where or if this is a Machine Learning project and want to make sure apps for this project only runs on GPU enabled nodes.
- Make sure developers do not try to expose their applications using something like app1.google.com and then come back to you saying they don’t understand why they can’t access their applications.
If it’s a critical application or environment, you also want to ensure you control default ingress and egress to applications deployed using this framework. This next step allows you to choose to enforce default network policies but also gives application owners the chance to customize the network policies for their applications post-deployment:
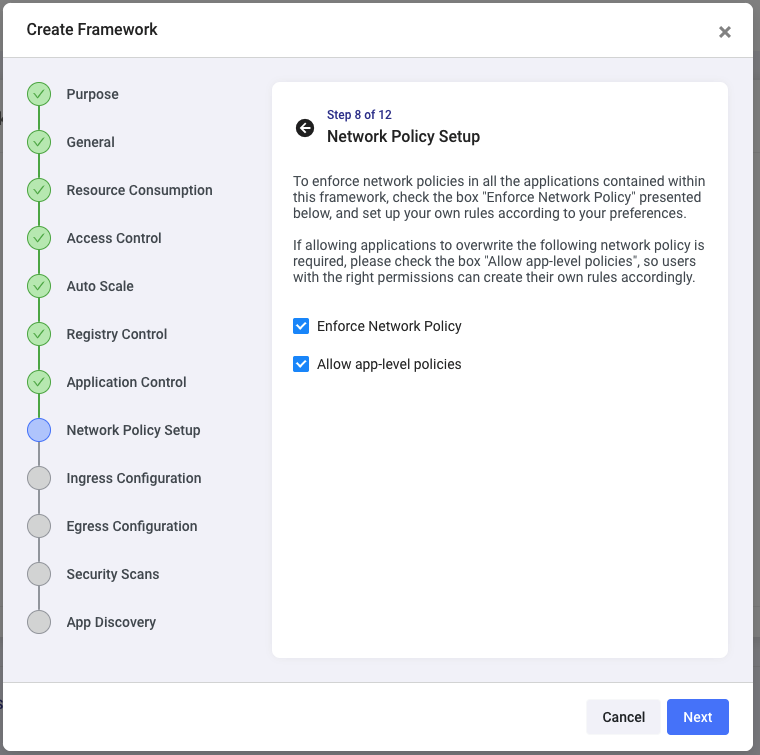
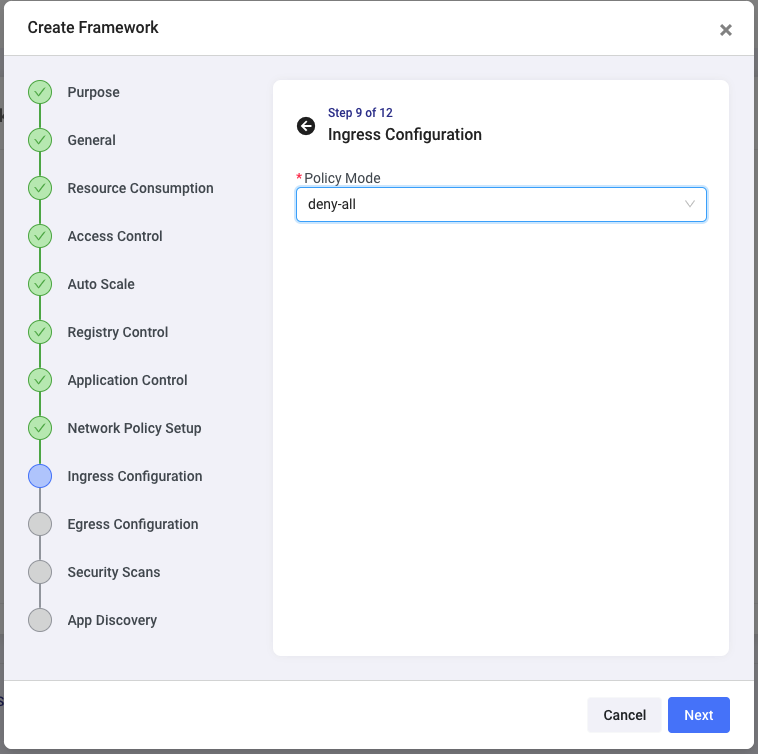
You can set the most restricted policy, such as deny-all for both ingress and egress, or custom policies only to allow traffic for applications deployed through this framework (or to the same namespace), or expand it to enable apps to communicate with specific other applications or frameworks, etc.
You will notice that you are easily setting these policies without dealing with any underlying ingress controller complexity.
The Security Scans step will enable you to make sure only specific vulnerabilities, if any, are allowed when applications are deployed through this framework:
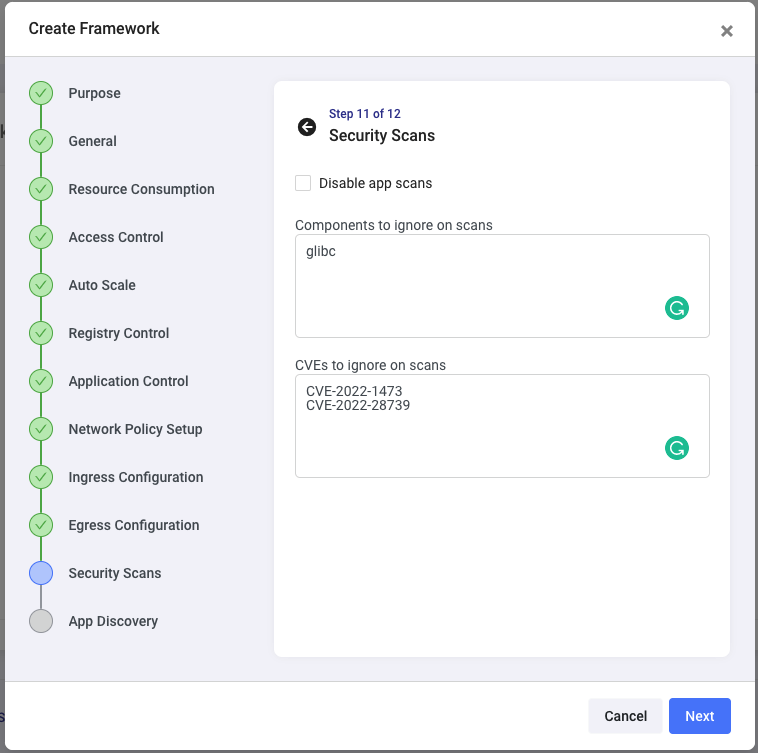
The next and final step enables you to discover existing applications that may already be deployed in this framework’s target namespace. This is not our case for this example, so click on Create.
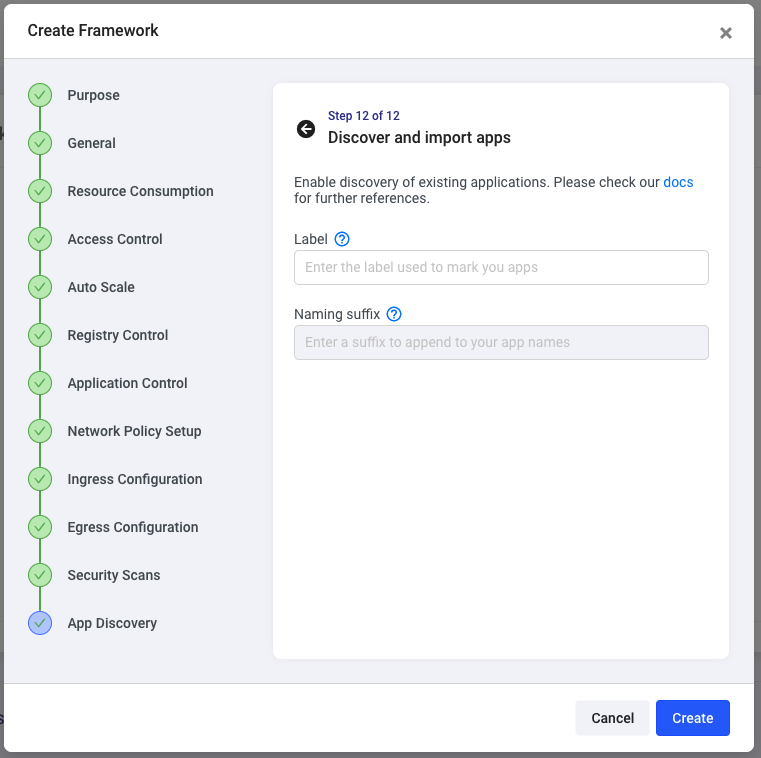
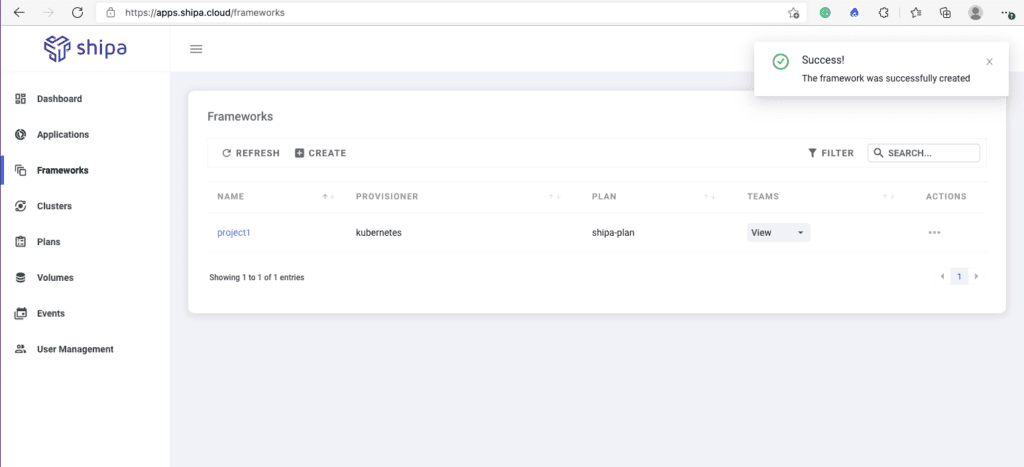
You can create multiple frameworks using the steps above and assign different security policies to each, helping you create a true multi-tenant and secure environment.
Connecting Framework to Cluster
After creating one or multiple frameworks, you can quickly connect them to a cluster.
Click on the Cluster option on the left menu and Connect Cluster.
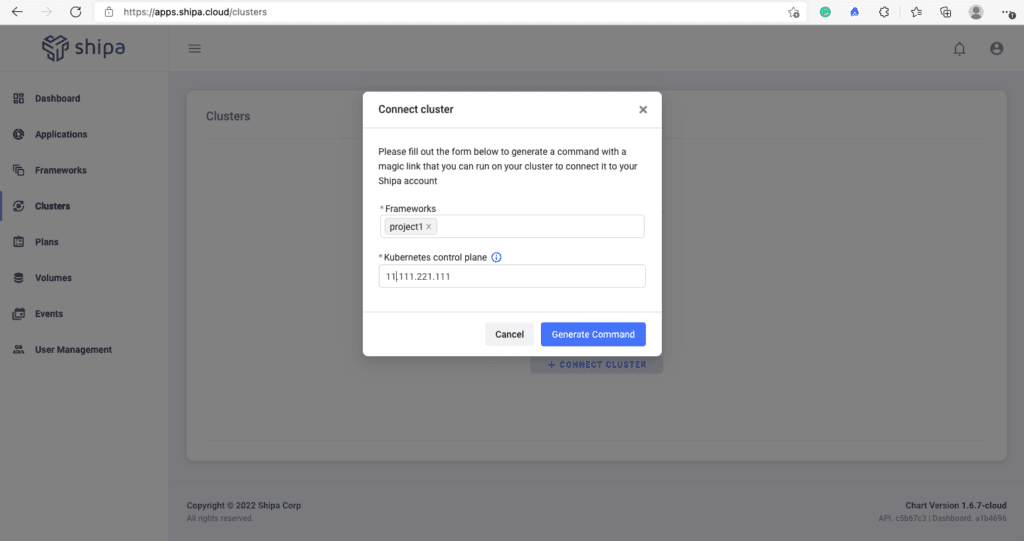
You just need to choose one or multiple frameworks you want to connect and your Kubernetes API address.
Clicking on Generate Command will give you a Kubectl command you have to run in the context of the cluster you are connecting the frameworks to.
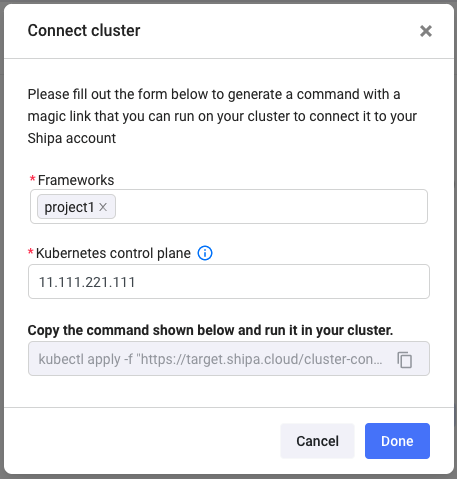
Once you run the command, Shipa will create a namespace where its services will be deployed alongside the namespaces for the frameworks you connect to this cluster.
Shipa will deploy its agent and start deploying its services. The process should take a couple of minutes to complete.
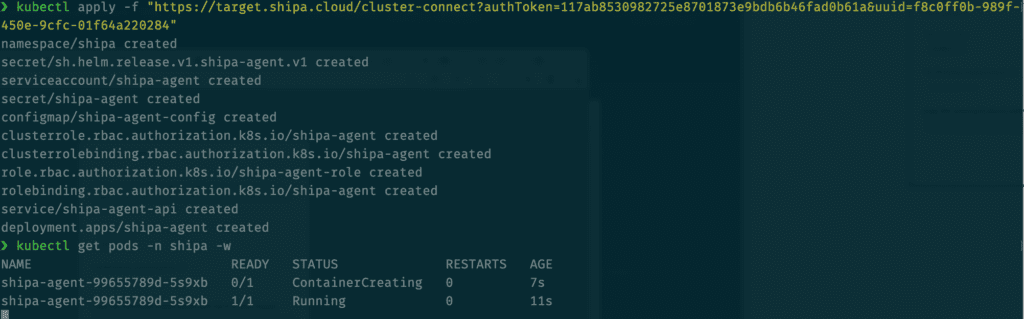
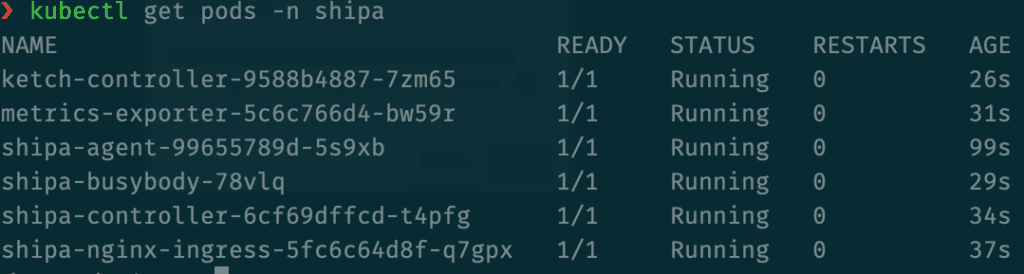
Once the process is complete, these are the services you will see running in the shipa namespace:
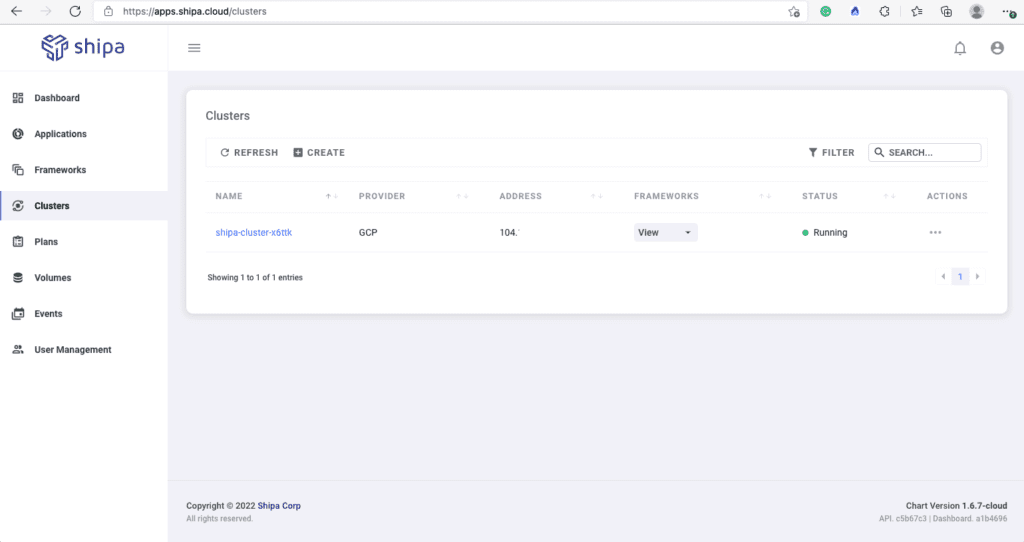
And if you refresh the cluster page in the Shipa dashboard, you should then see your cluster information available:
That’s it! You defined a complete set of policies without creating a single complicated Rego or Kubernetes object-level rule, giving you a scalable security model.
From here, you can connect policy changes to your incident and messaging tools by using Shipa’s webhooks. This will give you instant visibility into policies created, updated, deleted, connected to clusters, etc.
You can find details on using Shipa’s webhooks here.
Developer Experience
With your policies created and connected to a cluster, developers can now deploy their applications.
Deployments can be done using the Shipa dashboard or directly from your pipeline or IaC tool of choice, such as GitHub Actions.
You will notice that:
- Developers will now interface with a framework rather than clusters, which frees you up to change cluster providers, versions, components, and more without affecting the developer experience
- Policies will be automatically enforced both when applications are deployed and post-deployment, so it’s beyond just the Admission Controller stage.
- By pointing to the Shipa API, developers will have a much easier application definition they can use to onboard their applications, which will reduce the time you spend templating and managing endless YAML files for your developers.
- Because deployments are going through the Shipa API, developers, SRE, DevOps, DevSecOps, Platform, and other teams have centralized information about applications, ownership, policies enforced, application dependencies, service communication, and more, which will drastically facilitate the process of supporting applications post-deployment
Conclusion
You have enforced a comprehensive set of policies to a multi-tenant environment using a scalable architecture in just a few minutes.
This model will also give you centralized information about policies enforced across multiple clusters, teams, and applications, reducing the complexity of creating and managing policies for each cluster in a decentralized manner.
Last but not least, you now have a solid model that you can scale across your team without requiring you to spend several hours creating and maintaining complex infrastructure-level rules.
I hope this helped show you a solid option to address multi-tenancy in Kubernetes.